![]() 『検定システム』、『採点集計システム』、の開発請負 株式会社バイナリーのTopへ
『検定システム』、『採点集計システム』、の開発請負 株式会社バイナリーのTopへ
各種検定システムや採点集計システムの構築は、弊社の基幹業務です。
(財)日本英語検定協会様の『実用英語検定試験(通称:英検)』、(株)旺文社様の『大学入試模擬試験』などは、
以前はメインフレームによるシステムでしたが、当初より総て弊社が、全面的に支援・構築させていただいたものです。
これらのシステムの特徴は膨大なデータ件数にあり、1回につき100万件を超える、採点集計などは普通の事と言えます。
そのため要求されるノウハウは『高速処理』はもとより、『正確な採点と集計』『大量の成績表印刷』、また試験後には、
『合否検索』などなど…、数えたらきりがありません。
優にパソコン処理の範疇を超えており、中には数億件にも及ぶ過去の合格者検索まであります。
これらの業務を『数十年間』に渡りサポートしてきた『経験とノウハウ』が弊社の基本ソリューション構築の基盤と
なっていることは言うまでもありません。
メインフレームで培った処理技術のすべては、パソコンにも移植されており、あらゆる検定システム、採点集計システム、
成績履歴管理システムなどに『迅速に対応』できる開発環境を持ち合わせています。
弊社が開発した『ダイバース データシート(コピー用紙)』は、マークシート環境をもっと身近な設備で簡単に利用出来る
ようにと開発され、記述用紙でもなく、従来型マークシートでもない、両方の利便性を併せ持つ、多様性に優れたデータ
シートです。(後述)
従来のマークシート手法をコピー用紙で代用するだけの、他社ソリューションも多くありますが、弊社のデータシートは
単なる媒体変換ではなく、その書式やマーク手法、マークの解析方法に至るまで、改良と工夫を施したもので、この辺が
他社とは全く異なる点です。
『コピー用紙での代用』をPRするならば、何故、読取りスキャンする装置の精度と機種を限定するのでしょうか?
身近にある、どんなスキャン装置であっても、確実かつ正確に読取れることの保証は、一筋縄ではいきません。
ですが、それが出来て初めて、コピー用紙で代行することの、本来の目的が達成されるのです。
身近にある『複合コピー機』等でスキャンするだけで、シートの読込経費を全く掛けず、かつ、遊んでいる事務機器を
IT環境に於ける『主要入力装置』へと変身させてこそ、真のソリューションと言えるでしょう。
![]() ダイバース データ シート のサンプル
ダイバース データ シート のサンプル
《例えば、Placement Test》


《例えば、検定試験》
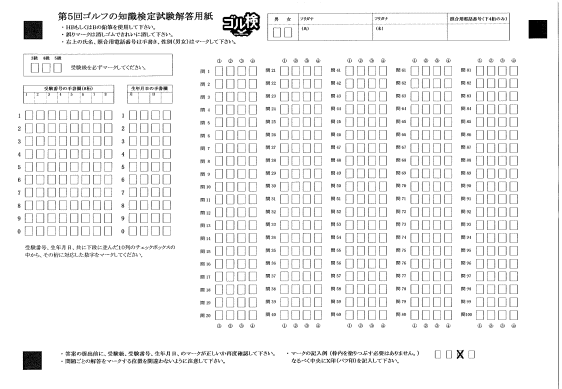
《例えば、アンケート集計》

《従来の楕円塗潰しシート、マーク欄が薄いため拡大表示であるが仕様は同一》

![]() データ シート の詳細仕様
データ シート の詳細仕様
市販の『スキャナー』でも読込めますが、お手持ちの『複合コピー機』あるいは『スキャナー付プリンター』
でも充分代用できます。出来れば手差しではなく、自動フィード機能があるものを推奨します。
専用シートの製作費が掛からず、設備投資も必要無く、その運用コストは今までとは比較になりません。
すべては、マークシートの環境を、身近で手軽な処理手段として利用いただくためのテクノロジーです。
《特長》
・ 精度の高い専用シート印刷は不要 (身近なプリンターで簡単印刷)
・ シートの材質も自由 (高級紙や厚紙は不要、再生紙の「コピー用紙」で充分)
・ 読取機器も自由(「複合コピー機」「スキャナー」「スキャン機能付プリンター」…、 メーカー原則不問)
・ 読取る内容も自由(通常伝票、テストの解答、アンケートの回答、その他…)
・ マークの仕方も自由(簡単な、レ点、×印、黒丸…、枠内を塗りつぶす必要なし)
・ 筆記用具も自由(鉛筆、シャープペンシル、ボールペン、万年筆…、但し消せないものは不利)
・ シートのサイズはA4版が基本(B5版は要ご相談)
その他に関連する複数の、特殊ソリューションによって、弊社の『文・教育ソリューション』は構成されており
互いに連係し合うことで、目標である『信頼性と独創性』を維持管理しています。
その中で代表的なものを紹介しますと、例えば、
![]() 『画像補正エンジン』
『画像補正エンジン』
保存の形式、密度、方向、ブレ、伸縮、歪、等々、提唱の『メーカー不問』のイメージ処理は大きな壁です。
しかも画素単位の補正処理のため、1シート分を解析し補正するには、それなりの補正時間を要します。
弊社の補正エンジンは、ファイル形式や密度を超え、画像の乱れを素早く補正し、すべて同一規格の
イメージ形式に統一変換することを目的としています。
《特長》
・記録形式(TIF,JPEG,PNG,GIF,BMP等…)、ファイル圧縮(ZIP等…)も判別
・記録密度(縦横の画素数,DPI等…)も判別
・イメージのトップ、レフトのマージン、傾き、伸縮、等も判別
・天地逆転(180度回転)シートの混入も判別
・最低60〜80シート/分、の高速補正スピード(使用PCの仕様により異なる)
![]() 『マーク解析エンジン』
『マーク解析エンジン』
マーク解析で難しいのは、筆記用具によるマークの濃淡の違いです。
濃いものを標準にすれば、薄いものは無視され、逆に薄いものを救うと、不要な汚れまで読み取ります。
弊社は自由な筆記用具も原則可能としているため、濃淡を基準としない特殊な解析方法を用いて、
人為的にマークした形跡があるか否かの判定も補佐的に行っています。
《特長》
・5mm x 6mm , 4mm x 5mm ,4mm x 4mm のマーク枠が基本
・3mm x 4mm , 3mm x 3mm 枠は要ご相談
・単独マーク欄は、1番濃いものを自動選択
・複数マーク可の欄は、最高で選択肢の数の1/2迄、濃い順に自動選択
![]() 『採点集計エンジン』
『採点集計エンジン』
マークの解析後に必要となるのは、採点集計環境です。
弊社は新しいテスト毎に、採点環境を追加する経費(採点プログラム作成料)の削減と、採点の信頼性の
確保を目的とした、汎用採点エンジンを用意しています。
このエンジンの実力は、かつて旺文社様のメインフレームで実施の『センター試験模試システム』の
採点エンジンをパソコン用に移植したもので、その精度と信頼性は保証付きです。
言い換えると、センター試験での数学並みの採点が出来ることになります。(数学の配点は煩雑)
また、集計履歴保存機能を備えており、これにより、後日の追加集計や作業分割を可能にしています。
《特長》
・自在な関連OR配点(論理和:〜か、もしくは〜)
・自在な関連AND配点(論理積:〜で、かつ〜)
・マイナス配点や順不同採点
・単元毎の採点と、自由な単元選択(必須、選択)
・正解値と配点は外付け管理(プログラムの修正不要)
![]() 『OCRエンジン』
『OCRエンジン』
最後にどうしても必要となるのが、シートの自動認識機能です。
運用時(読込時)に、シートを分類し仕分して処理するようでは面倒です。
『ごちゃ混ぜ』でシートをスキャンしても、内部で自動的に仕訳されることで操作ミスと手間が省けます。
このエンジンは、シートの上部に印刷されている、シート識別番号を自動認識することを目的としています。
《特長》
・シート識別の基本は任意桁の数字番号 (前項のサンプルを参照、例えば顧客番号2桁+科目番号2桁…)
・必要なら提出者IDの識別にも利用可能 (個人別のシートでIDと名前を事前に印刷…)
・識別数字は最高16桁程度とし、基本的に使用目的は自由
この他にも弊社では、様々な 『文・教育関連ライブラリー』 を保持しています。 RETURN to TOP![]()
システム構築のご意見やご要望は、いつでもお気軽にご相談ください。